What's Good for the Goose is Good for the GANder: An Application of SeqGAN
Earlier Post
Previously, we realized that it is difficult to backpropagate gradient updates to discrete generator outputs when applying GANs to areas such as language. Recent research suggests that we can mitigate this by enforcing a reinforcement learning policy to the generator model.
Sequence GAN
Sequence GAN (Yu et al. 2017) introduces a solution by modeling the data generator as a reinforcement learning (RL) policy to overcome the generator differentiation problem, with the RL reward signals produced by the discriminator after it judges complete sequences.
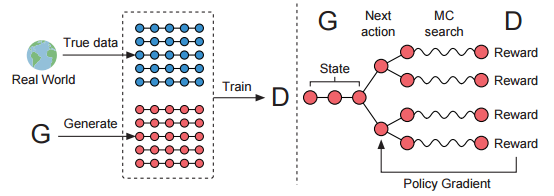
Figure 1. Diagram of Sequence GAN (source: Yu et al. 2017)
~ WIP ~
Persisting Problems
However, problems with this model persist, as the GAN training objective is inherently unstable, producing a large variation of results that make it difficult to fool the discriminator. Maximum-likelihood Augmented Discrete GAN (Che et al. 2017) suggests a new low-variance objective for the generator.